LLM for web developers (Part II - OpenAI API)
Check out Part I for general knowledge about GPT.
In this article, I’ll go through a few key APIs you need to know to build GPT applications! Reference OpenAI documentation and API reference for official up-to-date information.
Pre-requisite
- You need to create a free account on OpenAI, and generate an API key. (Note, the ChatGPT chatbot and the developer dashboard are totally separated).
- The API usage is not free, but OpenAI gives free credit to new users.
- Assuming you are familiar with JS/TS, Node, NPM.
OpenAI API overview
OpenAI currently offers the following models:
GPT 3,GPT 3.5,GPT 4: all the completion modelsEmbeddings: vectorize text content, this is very commonly used together with GPT.DALL-E: image generation modelWhisper: audio transcribing model
DALL-E and Whisper are for their use cases - image gen and audio. And in this blog, I’ll focus on only GPT and embedding
GPT: Completion vs ChatCompletion
In part I, all the examples used are Completion API - this is the original tech of GPT: “given some text, continue generating text following them”.
ChatCompletion is OpenAI’s alternative and improved GPT API, where they changed the input and output structure, and made it better at following instructions and answering questions.
Input/output structure
| Completion API | ChatCompletion API | |
|---|---|---|
| Input | You are a coding instructor, you answer coding questions that can be understand by beginners. |
Question: What is JavaScript?
Answer: | [ {role: “system”, content: “You are a coding instructor, you answer coding questions that can be understand by beginners.”}, {role: “user”, content: “What is JavaScript?”}, ] | | Output | JavaScript is a coding language used for web development. | {role: “assistant”: content: “JavaScript is a coding language used for web development.”} |
The Completion API is just using a plains string, while the ChatCompletion uses a JSON format (called messages), that clearly separates the instruction (system), the context and question (user) and the answer (assistant).
It makes the content more structure and easier to manage for users. And easier to understand for the model.
Better examples
Now that the messages are structured, it’s easier to add examples (one-shot), simply add one or more user and assistant pairs.
[
{"role": "system", "content": "You always start your answer with YO!"},
// This is a one-shot example pair
{"role": "user", "content": "Who is Michael Jordan?"},
{"role": "assistant", "content": "YO! Michael Jordan was an NBA player of Chicago Bulls, ..."},
// This is the actual question
{"role": "user", "content": "Who is Allen Iversion?"},
]system message
One super useful addition to ChatCompletion API is the system message, which - according to OpenAI - will be paid special attention by the model when answering the question. This is usually used for:
- Set overall profile (e.g. “You are a sport announcer, and you answer questions like you do in NBA games”)
- Set high level instruction (e.g. “You answer questions in a funny way, with jokes mixed in”)
How to choose?
There’s almost no downside of using the ChatCompletion API, I view it as the next-gen of Completion API. So I always use ChatCompletion now.
Besides, for newer models like GPT-4, OpenAI only offer the ChatCompletion API. Only older models has the Completion API.
API Parameters
If you look at the API doc, ChatCompletion API has quite some parameters. (most of them are the same for Completion API). But in most cases, you only need to care about:
messages(orpromptif you are usingCompletionAPI): obviously, this is the content / questions you are sending to the model.model: which model to use. Likely one ofgpt-3.5-turboorgpt-4. It’s mainly a trade off: “faster speed + cheaper price” vs “better result”. You can try both, compare results and performance, then choose which one to use.temperture: this controls the randomness, or say, “creativity” of the answer. Unless you want to do creative writing, for most cases, using0(most stable) is the best for reliability, and avoiding hallucination (i.e. making up incorrect content).
Token limit
Token limit is one of the first issue you will face when building any real applications. All GPT models have token limits - which is the most amount of tokens you can have in your prompt/messages.
Token is the unit of content in GPT models, you can read more here, and try out the tokenizer. It’s roughly 3-4 letters in English content.
Different models have different token limit, from 4000, 8000, to 16k, 32k, and Claude has 100k, etc. OpenAI model token table.
8k tokens (gpt-4 base model limit, ~30k letters) may seem quite a lot, but if you want to build a real application, it’s usually not enough. For example, a medium academic paper is ~4000 words, that is already roughly 25k letter. If you want to build an “Ask Paper”, you can easily exceed the token limit. That’s where embedding comes in.
Embeddings
Embedding is another critical API for any GPT related applications. It make text into a vector (i.e. an array of numbers) based on its meaning. (see the examples in my Part I blog). Once you have vectors, you can do all the math things - especially similarity search - for any given text, you can use vector distance to find the most similar text in your dataset.
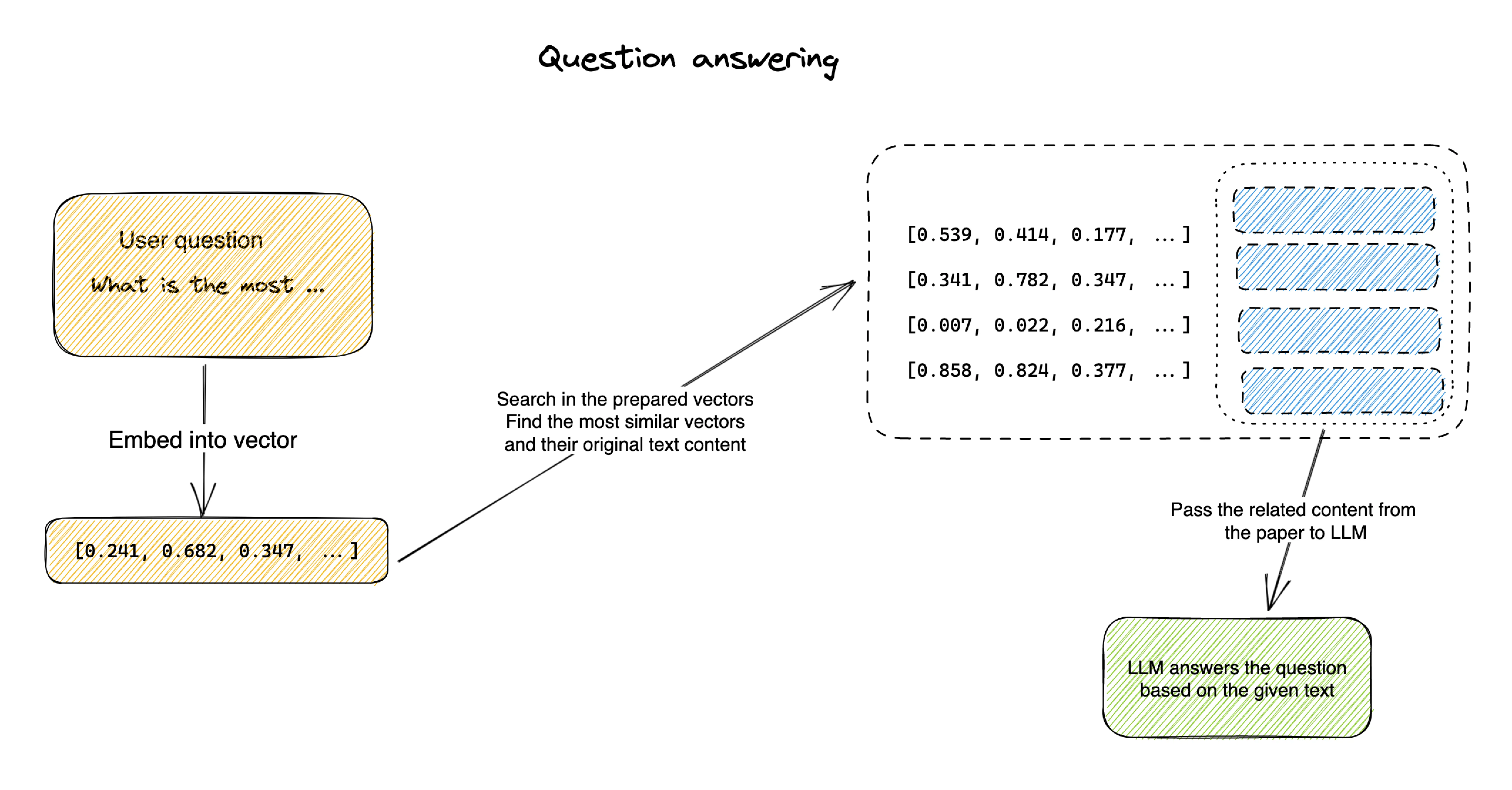
As noted above under token limit, GPT model has a relatively small content size limit. To overcome this, we use embedding. Here’s how it works, using an example of “Ask question against a paper”
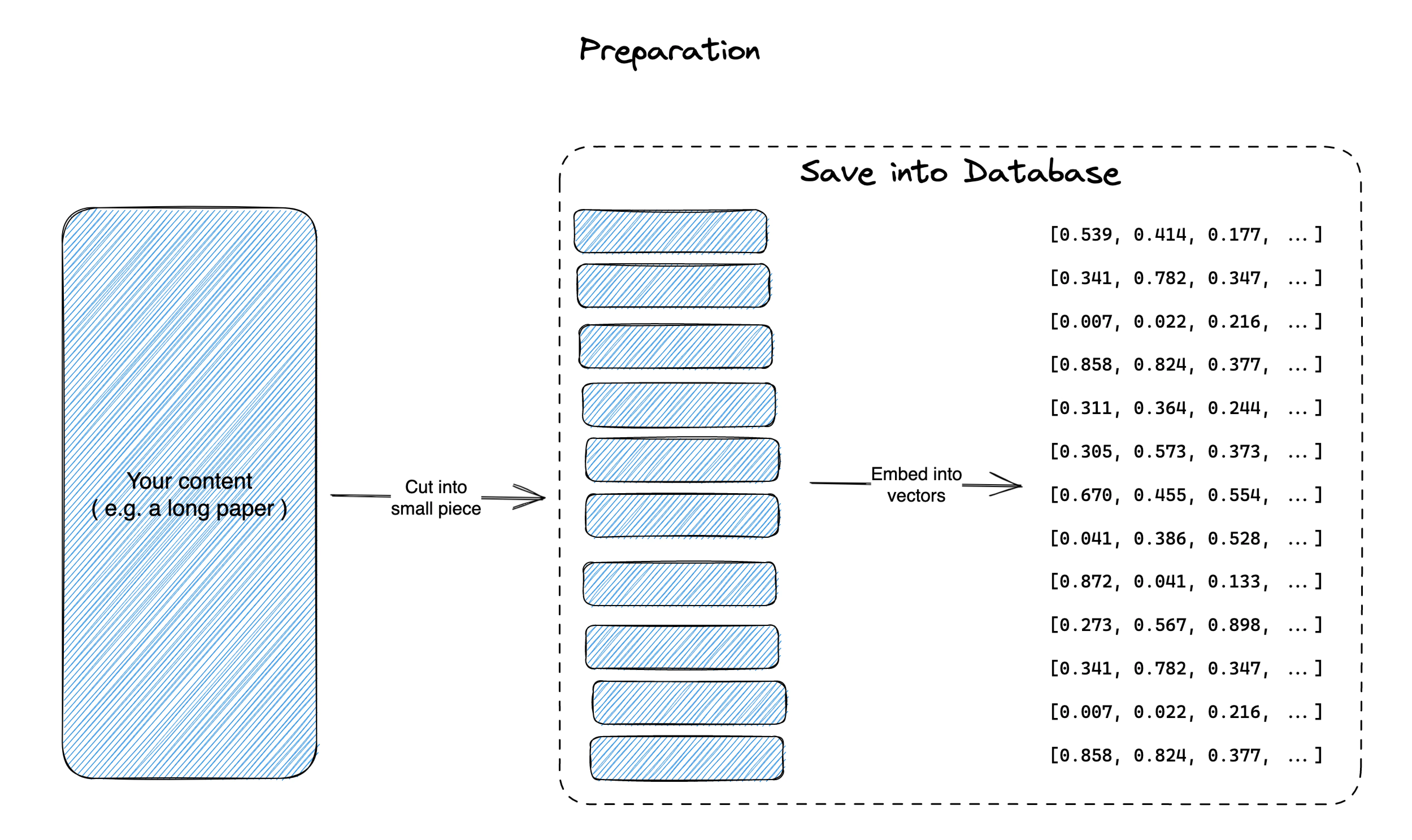
- Preparation
- We first chunk the original paper into pieces. You can chunk it by sections, or paragraphs, etc. (it’s a science + art on how you chunk the content, and depends a lot on what the content is. I can talk a lot about this later)
- Then we use embedding to convert each chunk into vectors. You would usually save those into a database - there are many newly launched “vector database”, you can also use
pgvectoron Postgres.
- Answering
- Now, then user asks a question, you go into your embeddings, and find the most related content (i.e. similar vector) to the question. and then only put the top N (that doesn’t exceeds token limit) to your LLM model.
- Now your model got a few pieces from the original content that is related to the question, AND within the token limit. It could start answering the question.